
This post is a summary of the presentation that Olga C. Santos and I gave in the EuroIA 2015 Summit in Madrid on 24th September, where we discussed how personalization enhances the user experience and how information architecture can help in the process.
Olga C. Santos has a Ph.D in Artificial Intelligence, and I have a Ph.D in Industrial Engineering. She is primarily focused on Academia, while I design experiences for the industry. Although our profiles, backgrounds and jobs are quite different, we both share user-center-design methodologies in our projects, and personalization is just one of them.
What is personalization?
Personalization is the process of tailoring content and functionalities to individual users’ needs, characteristics and preferences to anticipate interactions and, consequently to increase conversion, satisfaction and retention. By anticipating interactions, the system becomes faster and easier to use, because users don’t waste their time with all the possible options they have, and they just focus on what the system considers it is best for them to do.
A trendy term nowadays is Business Intelligence (BI), or the science of transforming data into meaningful and useful information for companies. Both BI and personalization share artificial intelligence techniques and tools. However, personalization steps a little bit further by adjusting the interface to each user in real time.
Others approaches that are not personalization
In the beginning, systems were made the same for everybody, it did not matter if you were a new user or an expert: the products had the same interface for everybody.
Then, some macro-segmentation was introduced in the design. For example, if you visited a university website, you were prompted to say if you were a student or a professor to get a different version of the website in each case. Sometimes a cookie was set in the browser, so the next time you visited the site, you directly accessed to the specialized version you had previously chosen.
The evolving version of macro-segmentation is micro-segmentation. This concept comes from advertising, and it consists of providing certain contents and functionalities to the users depending on their profiles. This is not like the user choosing between the student or the professor portal in the university website, it is about all the site automatically adapted to this user’s profile. Micro-segmentation gathers data from cookies and their social network identities. Then, the system accesses to sensitive information and depending on that information, it sets a group of rules to show one piece of information or other. The goal in this case is to improve conversion.
Another step is allowing the users to set their preferences in the system. That is customization. Although people often use both words for the same concept, they are not the same at all. Users customize their experience explicitly by stating their interests and preferences, while the personalization is directly provided by the system based on the experience, without users lifting a finger.
Personalizing UX vs. Customizing UX
Imagine it’s 2 in the morning, I am writing my Ph.D so I need concentration. My headphones are plugged in and I select some classic music to play. Yesterday, in the evening, I was partying with friends at home and we were listening to disco music in high volume.
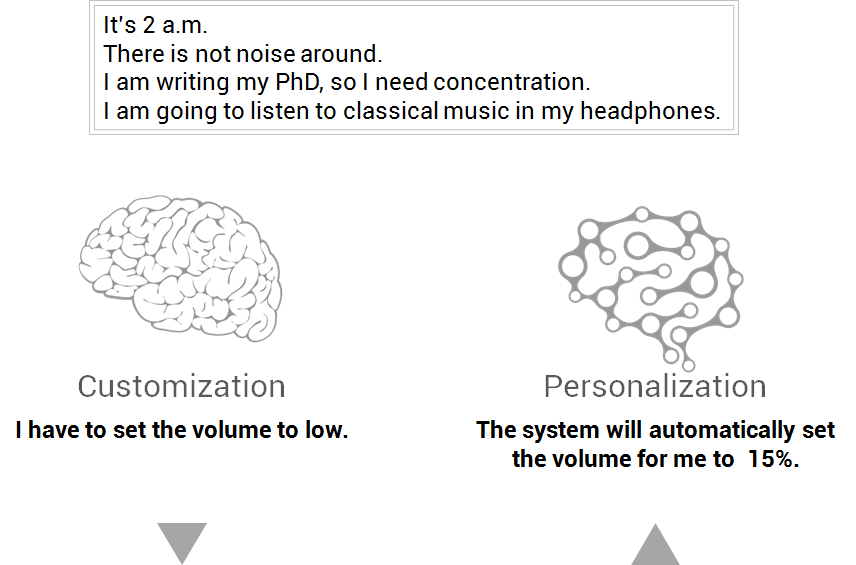
In the customization scenario, if I don’t want high volume, I have reduce it. That is, I have to do something to accommodate the system to my particular circumstances. But, if the system had a personalization layer, it could have recognised the situation and, based on previous experiences (mine or from other people), set the volume automatically to an appropriate level.
In both scenarios, the result is the same: you got the volume set to a low level, but which one has the best user experience? It depends on the person, of course, but the user’s flow is better with the personalization.
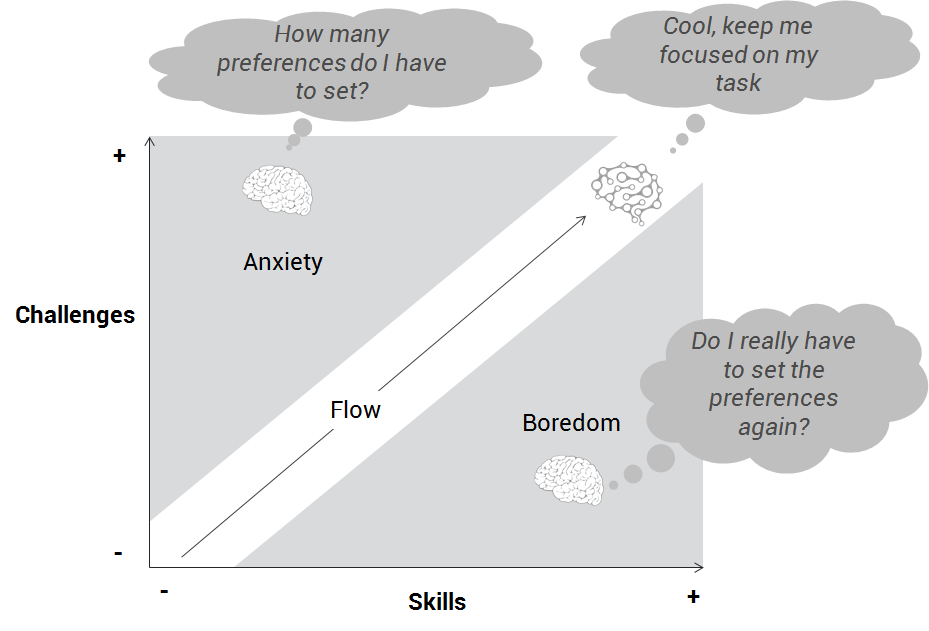
In this classic flow diagram from Mihaly Csikszentmihalyi, we show how the personalization allows the user to be focused on the task. If the user has too many preferences to adjust, it will cause anxiety. But if the user has to adjust the preferences very often, she will be bored. The goal is that the user stays focused on what she is doing.
However, be careful with generalization. Let’s take the same situation as before, but today I want full silence, and the system does not know it.
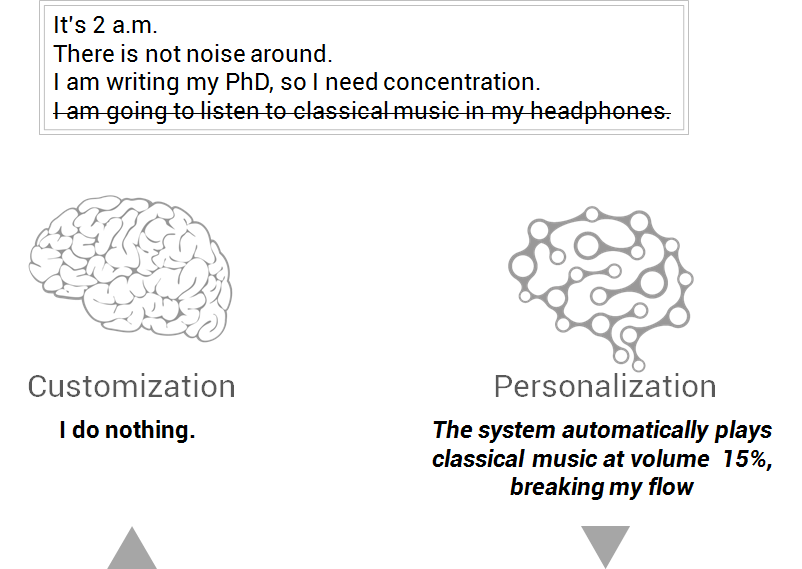
In the customization scenario, I don’t have to do anything, just focusing on my task. In the personalization scenario, the computer automatically plays Mozart in a low volume because it considers that the situation is similar than before. Maybe I like it or maybe I don’t, but it has not been my decision. If I don’t like it, I have to stop what I am doing, quit that music and look for this situation not to happen anymore. This is taking time, effort and attention out from me, keeping me away of my flow.
Bad user experience in this case for the personalization, though a good personalization system will learn from this failure to make better decisions in the future.
How to personalize experiences
Creating personalization is not different from cooking a recipe.
![]()
- First, we will need some ingredients. Our raw material is three flavours of data: the system data, the user data and data from other users.
- Then, we have to cook the data in the processing step.
- As a result of the processing we deliver the personalization, that is, the meal.
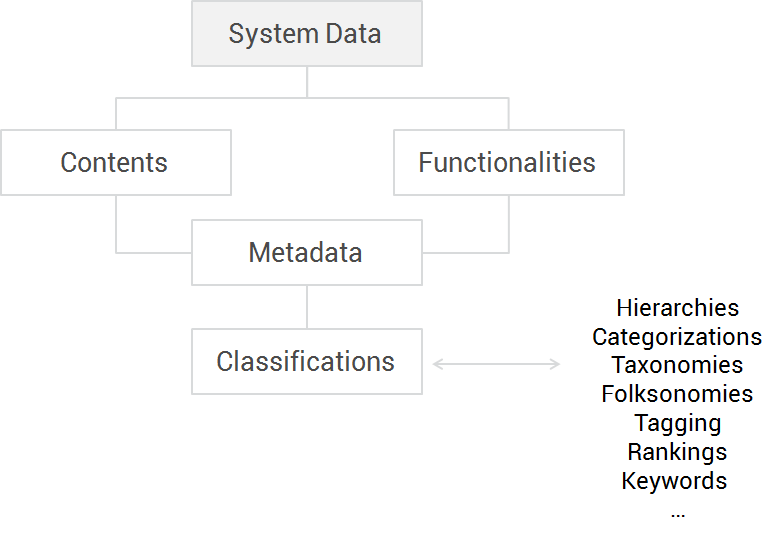
System data
When we talk about system data, we are talking about the contents and functionalities that our system has. These contents and functionalities should be provided with metadata, that allow the system to classify them: for example, new or old contents, functionalities for novels or experts, etc. This classification can be done manually by the system administration or by users, or automatically with algorithms.
User data
There are several methods to gather data from the user:
- By asking the user to set her preferences in forms, the same technique used as in customization. This technique is bothering for the user, and there are many drops-out in this step, so if you use this method, keep forms as simple and short as you can.
- Cookies provide useful information on what the user did in the session, but it is difficult to know when the user jumps from one device to another, or when many people use the same device.
- Other technique is to analyse the click-stream the user performs. This technique is also used in micro-segmentation, and you have to learn some analytics to correctly read and summarize information. The most interesting aspect of this technique is that you can create rules depending on the user behaviour. For example, some travelling websites rises their prices in the second or third interaction of the user with the site, to motivate the users to complete the purchase before the price rises again. In turn, in certain e-commerce sites, when a user visits several times the same item, and spends a lot of time comparing it with other items or shops, she may receive a discount coupon to motivate her decision.
- The fourth way to gather user data is to ask for feedback on what theuser is doing right now. For example, when the user clicks on facebook’s “I like” button in a cooking recipe like this one. On the one hand, her friends will see this content and maybe they come to this site to get more information. But on the other hand, the same user will probably get recommendations on other cooking recipes in her facebook timeline, not only from this site, but from other cooking websites.
- Finally, we can analyse the context of the user by getting continuous flows of data she generates, for instance content created (emails she has composed), transactions performed (payments with her credit cards), her biometrics (physical data traced with wearables) or the context where she lives in (her connected car trips records). When the goal of the data exchanged by these devices is to improve the user experience, it’s called “Internet of Me”.
Data from other users
Here we refer to other users of the system whose interactions are also recorded and processed. When there is a critical mass of users in a system, the system can match the data of a given user with the data of other users who have similar features to this user, and then deliver the personalization in a way that the system predicts to be statistically successful for this user based on what similar users did in the past. This is called collaborative filtering.
Currently systems are also gathering data from users outside the own system. For example, some news websites adapt the contents in their front-page depending on what is trending topic in twitter.
Sometimes users are aware that their interactions affect in the personalization of the interface of other users. For instance in Reddit, when users vote a post, they assume that they are changing other users’ contents. But other times users are not aware that their interactions are recorded and used. For example, Amazon collects information on your purchases to recommend other users similar to you to do the same purchase.
Processing
As we have seen, data collected are getting more and more complex everyday. Widely used personalization approaches such as collaborative filtering might not be sufficient. Thus, when the data arrives to the processing step, two procedures should happen:
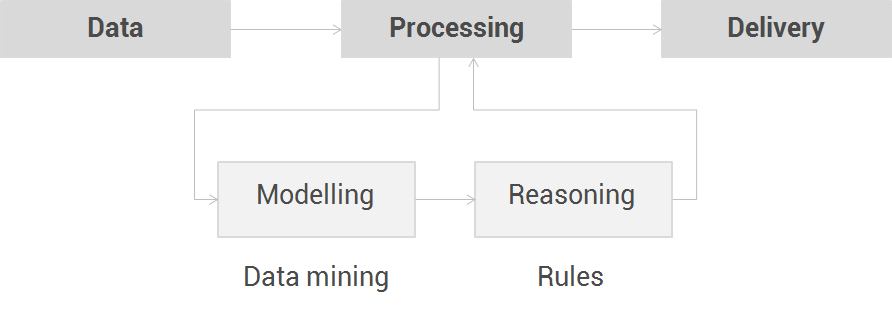
First, the features of the user can be extracted from the data collected with data mining algorithms to build or update a model that represents the user.
With this information, the system can apply rules to match the appropriate contents and functionalities for a given user in a given context. This reasoning produces the personalization that has to be delivered.
Besides, there are two trendy concepts in processing taking advantage of the Internet of Me.

The first one is called affective computing, which helps the system learn a new aspect about the user: her emotional state. In this way, systems can be personalized in an empathic way. Affective computing combines multiple data sources such as physiological data, facial expressions, biomechanics data and so on.
The second concept is Big Data. This new paradigm deals with large Volumes of data flows that continuously arrive at high Velocity and come in a Variety of formats, as it happens in affective computing. These enriched and complex data exceeds the processing capacity of previous processing technologies, and thus, rely on advance processing approaches.
Delivery of the personalization
The last step of the personalization path is the delivery step. There are two ways of doing it: recommendation and adaptation.

In the first type, the recommendations, the system suggests the user to do something because it predicts the user will like it; and the user can decide whether to follow the recommendation or not.
The other way to personalize the experience, much more subtle and perhaps controversial, is the adaptation. In this case, the system automatically adds, removes or modifies contents or functionalities based on what it knows about the user.
In both cases, the system needs to “show the ‘right’ thing at the ‘right’ time in the ‘right’ way to the ‘right’ person”.
Artificial Intelligence seeks help in Information Architecture
Traditionally, personalization has been designed by artificial intelligence experts, who control all the steps of the process. Everything is considered quantitative and depends on the data. In this context, there exists several issues that can challenge Information Architects:
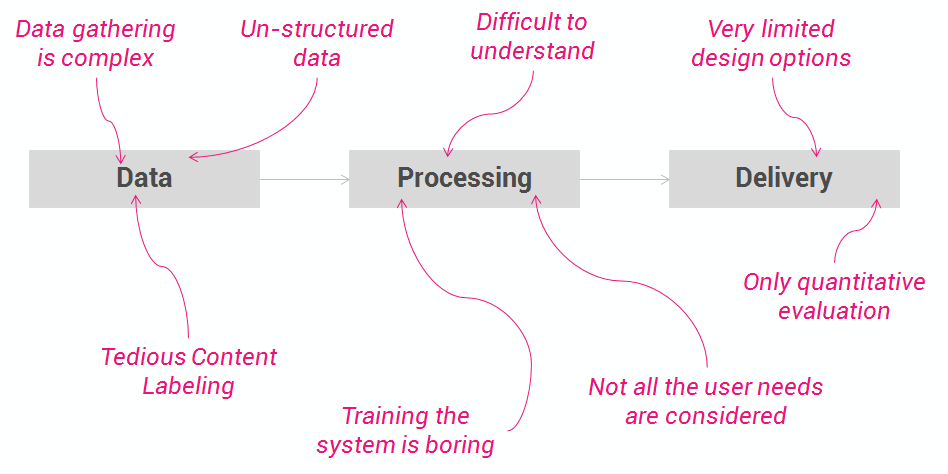
- Data gathering is complex, its labeling is tedious and many data are un-structured and difficult to analyse and mash-up.
- In the processing step, personalization faces three problems: First, when the system is new, it’s complicated to train it without burning down the users expectations. Second, understanding rough data in order to decide the algorithms that apply best is quite difficult, specially in the emerging Big Data paradigm. And third, not all the needs or features are considered in the user modelling, so there are still gaps to fill in with relevant knowledge that can enrich the personalization.
- Lastly, in the delivery step, there are only two alternatives (recommendation and adaptation), and interfaces are often not visually appealing. Besides, only quantitative information is usually taken into account in the evaluation of the personalized experience.
So the challenge now is: “how can Information Architects help Artificial Intelligence experts to create better personalization experiences?” Here are some ideas we propose to cope with these problems.
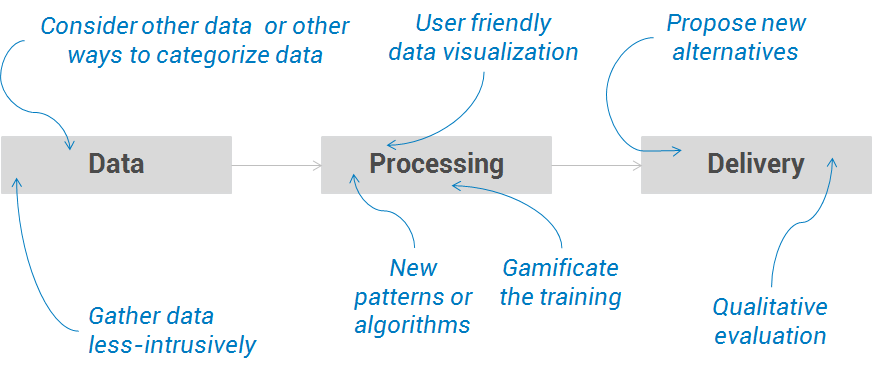
- The first challenge focuses on the problem of the ingredients, which were the complexity and tediousness of gathering data, often un-structured and difficult to analyze and mash-up. In this sense, Information Architecture has methodologies such as quick protyping, to explore new ways of gathering data in usable, elegant and non-intrusive ways. Besides, other data that have not been used yet, or new ways to categorize data, can be considered with user research like shadowing or card-sortings sessions.
- In the processing step, there were three problems. First, when the system is new, it’s complicated to train it without burning down the users expectations. In this case, gamification techniques can be applied to cope with them. This is what Google did, for example, to tag photos and to teach its engine how to recognise them. The second problem is understanding rough data. Here, Information Architects can provide user friendly data visualizations, creating tailored charts and graphics to provide a picture of the data collected. And the third issue in processing is the need to consider other needs or features in the user modelling. In this sense, qualitative research with service design techniques can elicit new needs or features that can lead to developing new algorithms or patterns.
- Finally, regarding the delivery step, Information Architects can help in complementing the quantitative evaluation with qualitative insights to measure the impact of the personalization. And lastly, maybe the more challenging one, that is finding new alternatives to deliver the personalizations apart from the recommendation and adaptation approaches.
With great power comes great responsibility
To this point, we have showed some of the benefits that personalization can bring, but… “with great power comes great responsibility”. Here there are some issues that have to be considered when jumping into personalization.
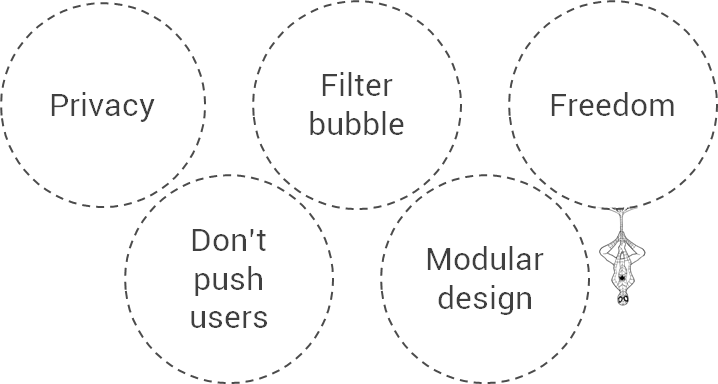
- Most of the users fear that their data might be lost, stolen or exposed, so security must be a priority in any design. Remember that we all
can beare monitored in all aspects of our life. The system who controls all data will be able to know where the user is, how she feels, where she is looking at, and almost what she is thinking… Yes, this system may improve user experience, but we are loosing our privacy as well. - Personalization can create a “filter bubble” that prevents people from accessing to other viewpoints beyond their own, or getting only facts which confirm their existing opinions. Sometimes we should break that bubble to explore new directions and enrich our perspective.
- Some users don’t like to be profiled, and prefer the freedom of choosing by themselves, so it’s mandatory to provide mechanisms to avoid the personalized experience.
- When designing a personalized system, it relies on users doing a lot of interactions like filling in heavy forms or navigating intensively. But on the other hand, users want the system to guess what they want without them having to lift a finger. Designers must avoid pushing users too much to provide data, and manage the risk that sometimes the system inferences might be wrong.
- Finally, when there are so many possibilities in the contents and functionalities, visual design is affected. We can’t assume two different users using the very same product, so we have to work with modules like LEGO bricks, that fit one into another in an usable and elegant way.
So, with these challenges and issues in mind, Artificial Intelligence and Information Architecture should be together when personalizing user experiences. This collaboration can enable companies to increase conversion, satisfaction and retention. And consequently, their profitability.